
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- centos7
- AWS
- 로키
- 객체지향
- IaaS
- OOP
- 프로젝트
- eks
- 구축
- fargate
- kubernetes
- rocky
- 젠킨스
- serverless
- app&desk
- 서버 베이스 컴퓨팅
- sagemaker
- jenkins
- server base computing
- 오픈스택
- 가상 데스크탑 환경
- 쿠버네티스
- microservices
- eslint
- 마이크로서비스
- 머신러닝
- openstack
- no-param-reassign
- 설치
- xenserver app&desk
- Today
- Total
IT
[eks, fargate, sagemaker] 3. Machine Learning 파트 구축 - Microservices구축시 EKS 와 Serverless 비교 및 Machine Learning Service 확장 프로젝트 본문
[eks, fargate, sagemaker] 3. Machine Learning 파트 구축 - Microservices구축시 EKS 와 Serverless 비교 및 Machine Learning Service 확장 프로젝트
abcee 2019. 4. 23. 02:423.4 구축
ML 확장 구축은 서비스를 신속, 유연하게 확장할 수 있도록 하는데 목적을 두고 진행했고, 모두 SageMaker의 Jupyter Notebook을 통해 Python Code로 구현되어 있다.
3.4.1 SageMaker를 통한 Machine Learning 학습
ML 학습은 SageMaker를 통해 총 3단계로 이루어 진다.
1. 인스턴스를 통해 DynamoDB로부터 데이터를 불러와 전처리한다.
2. 해당 데이터가 ML 학습에 적합한지 분석한다.
3. 여러 ML 훈련을 통해 최적의 ML 알고리즘을 선택하여 모델을 생성 및 저장한다.
DynamoDB Data 전처리
[그림 3.4-1]과 같이 Python boto3 api를 통해 설문조사 데이터가 저장되어 있는 DynamoDB survey 테이블에 접근하여 필요한 데이터만 S3에 저장한다.

데이터 분석
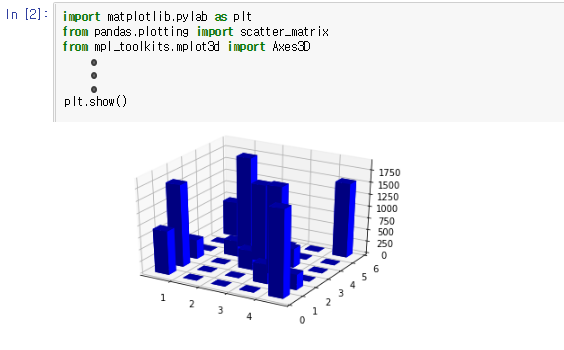
[그림 3.4-2]와 같이 python matplotlib api를 통해 데이터 히스토그램을 보고 ML에 적합한 데 이터인지 확인한다. [그림 3.4-2]에서는 3차원 히스토그램이 각각의 X축(연령대)마다 두각을 보이 는 Y축(평점) 데이터가 있음이 나타나 ML 학습에 적합하다 판단했다.
학습 및 모델 저장
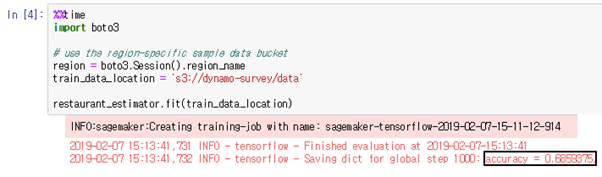
전처리된 데이터가 ML 학습에 적합하다 판단되므로 [그림 3.4-3]~[그림 3.4-5]의 총 3단계 과 정으로 ML 학습이 진행되며, [그림 3.4-6]~[그림 3.4-8]과 같이 학습 모델을 저장한다. 현 프로젝 트에서는 tensorflow의 LinearClassifier 알고리즘을 선택하여 학습을 진행하였고 0.68의 accuracy 를 얻었다.
[그림 3.4-3]과 같이 알고리즘, 학습 인스턴스의 HW스펙, 학습 단계 등을 설정하여 ML 학습기 (estimator)를 만들고 학습 데이터가 위치한 S3 경로를 입력하여 학습을 시작한다.

학습을 시작하면 Amazon SageMaker의 [교육]-[훈련 작업] 탭에서 [그림 3.4-4]과 같이 작업 중 인 훈련을 볼 수 있다.

훈련이 완료되면 [그림 3.4-5]와 같이 학습 결과를 Log를 통해 볼 수 있다.
ML 학습기(estimator)를 만들 때 [그림 3.4-7]과 같이 학습 결과가 저장될 S3 경로를 지정하면 해당 S3 경로에 ML 모델이 저장된다.

모델 데이터 위치의 S3에 진입하면 [그림 3.4-8]처럼 생성된 ML 모델을 확인할 수 있다.

3.4.2 SageMaker를 통한 Machine Learning 서비스
사용자에게 서비스하기 위해서는 ML 예측 Serving Server를 만들고 예측을 요청할 수 있도록 Endpoint를 구성해야 한다.
Serving Server 생성 및 Endpoint 구성
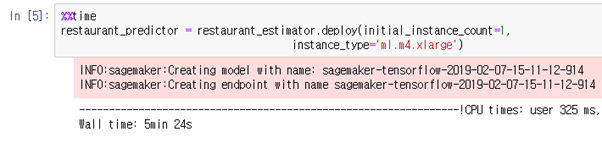
ML 학습이 완료된 ML 학습기를 통해 아래 [그림 3.4-8]처럼 예측기를 생성할 수 있다. 이때 예측기의 HW 스펙은 ML 학습기와 별도로 지정해주어야 한다. ML 예측기를 배포하면 SageMaker 의 model과 endpoint가 구성된다.
[그림 3.3-9]과 같이 Amazon SageMaker의 [추론]-[모델] 탭에서 생성된 모델과 저장된 위치를 확인할 수 있다.

[그림 3.4-10]과 같이 Amazon SageMaker의 [추론]-[엔드포인트] 탭에서 생성된 앤드포인트와 접 근가능한 URL을 확인할 수 있다.

serving 테스트
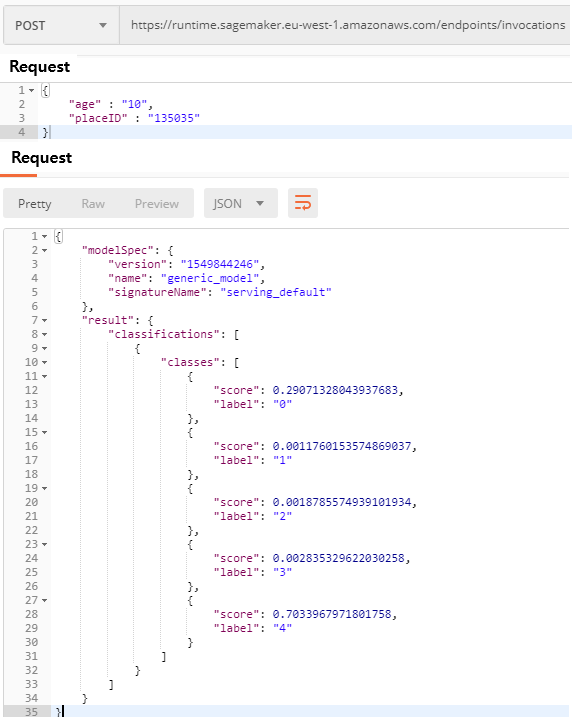
ML 예측 Serving Server가 정상 작동하는지 [그림 3.3-11]처럼 python api로 우선 테스트를 한다.

Python api가 작동하여 예측이 정상적으로 이루어 진다면 [그림 3.4-12]와 같이 endpoint의 HTTP URL을 통해 예측 API를 호출하여 테스트한다.
3.4.3 기존 인프라에 결합 및 서비스 변경
기존의 설문조사 서비스는 [그림 3.4-13]에서 보이듯이 고객의 설문응답 만을 받는 WEB UI를 제 공하였다. 서비스 확장에 따라 WEB UI에서 설문자의 연령대를 기준으로 ML 예측 Serving endpo int에 특정 레스토랑의 예상 평점을 요청하여 [그림 3.4-14]와 같이 상위 5개의 레스토랑을 보여 주는 서비스로 변경되었다.





